Happy Birthday To Me!
Happy Birthday To Me!
Today is my birthday. To celebrate I decided to look at what was in the news on January 27 every year since I was born. Mainly I want to see if the news were positive or negative.
Getting the data
I start buy creating a list of dates. I feel like there is probably a more straightforward way of doing this but I am currently obsessed with map so this is how I did it.
dates <-map(list(0:30), ~ymd("2018-01-27") - years(.x)) %>%
map(~as.list(.x)) %>%
flatten()The next step is to actually get the data. I used the get_guardian command from the guardianR package to get all articles. You need to register at http://open-platform.theguardian.com/access to get the API but this only took a few minutes. I get a few warnings about “Unequal factor levels” but I ignore them because this is most likely because I can’t find any articles for a few of the earlier years.
The data need some cleaning.
glimpse(theguardian_jan27)## Observations: 5,536
## Variables: 27
## $ id <chr> "uk-news/2018/jan/27/diners-rescued-in-bo...
## $ sectionId <chr> "uk-news", "australia-news", "lifeandstyl...
## $ sectionName <chr> "UK news", "Australia news", "Life and st...
## $ webPublicationDate <chr> "2018-01-27T00:43:29Z", "2018-01-27T04:30...
## $ webTitle <chr> "West London flooded as burst pipe forces...
## $ webUrl <chr> "https://www.theguardian.com/uk-news/2018...
## $ apiUrl <chr> "https://content.guardianapis.com/uk-news...
## $ newspaperPageNumber <chr> NA, NA, "72", "6", "65", "55", "85", "83"...
## $ trailText <chr> "Fire crews deploy rescue boats in Hammer...
## $ headline <chr> "West London flooded as burst pipe forces...
## $ showInRelatedContent <chr> "true", "true", "true", "true", "true", "...
## $ lastModified <chr> "2018-01-27T00:51:54Z", "2018-01-27T04:33...
## $ hasStoryPackage <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N...
## $ score <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N...
## $ standfirst <chr> "<p>Fire crews deploy rescue boats in Ham...
## $ shortUrl <chr> "https://gu.com/p/823jc", "https://gu.com...
## $ wordcount <chr> "188", "470", "1517", "727", "417", "692"...
## $ commentable <chr> "false", NA, "false", "true", "true", "fa...
## $ allowUgc <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N...
## $ isPremoderated <chr> "false", "false", "false", "false", "fals...
## $ byline <chr> "Patrick Greenfield", "Christopher Knaus"...
## $ publication <chr> "theguardian.com", "theguardian.com", "Th...
## $ newspaperEditionDate <chr> NA, NA, "2018-01-27T00:00:00Z", "2018-01-...
## $ shouldHideAdverts <chr> "false", "false", "false", "false", "fals...
## $ liveBloggingNow <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N...
## $ commentCloseDate <chr> "2018-01-30T00:45:00Z", NA, NA, "2018-01-...
## $ body <chr> "<p>People have been evacuated from their...First of all, I want to change the variable names so that they have underscores instead of capital letters.
df_names <- names(theguardian_jan27)
snake_names <- to_snake_case(df_names)
names(theguardian_jan27)<- snake_names
names(theguardian_jan27)## [1] "id" "section_id"
## [3] "section_name" "web_publication_date"
## [5] "web_title" "web_url"
## [7] "api_url" "newspaper_page_number"
## [9] "trail_text" "headline"
## [11] "show_in_related_content" "last_modified"
## [13] "has_story_package" "score"
## [15] "standfirst" "short_url"
## [17] "wordcount" "commentable"
## [19] "allow_ugc" "is_premoderated"
## [21] "byline" "publication"
## [23] "newspaper_edition_date" "should_hide_adverts"
## [25] "live_blogging_now" "comment_close_date"
## [27] "body"I am also going to get rid of some variables that I don’t need.
theguardian_jan27 <- theguardian_jan27 %>%
select_if(function(x) !all(is.na(x))) %>% # Drop columns with all missing values
select_if(function(x) !(is.factor(x) && nlevels(x)==1)) # Drop factors with only one levelTime to look at the titles using tidytext. I want my analysis to be done by year so I create a new variable with the year of web publication.
theguardian_jan27 <- theguardian_jan27 %>%
mutate(web_publication_year=year(web_publication_date))
tidy_theguardian_jan27<- theguardian_jan27 %>%
unnest_tokens(output=word, web_title, to_lower = TRUE)
cleaned_theguardian_jan27 <- tidy_theguardian_jan27 %>%
anti_join(stop_words, by="word") # remove stop words (words that are very common)
cleaned_theguardian_jan27 %>%
count(word, sort = TRUE) %>%
head(10)## # A tibble: 10 x 2
## word n
## <chr> <int>
## 1 â 469
## 2 review 212
## 3 uk 89
## 4 cup 80
## 5 media 75
## 6 video 73
## 7 letters 72
## 8 day 70
## 9 london 64
## 10 david 63As you can see the most common word is just the letter a with a hat. Since it is a not a real word I am going to remove it.
cleaned_theguardian_jan27 <- cleaned_theguardian_jan27 %>%
filter(word!="â")
cleaned_theguardian_jan27 %>%
count(word, sort = TRUE) %>%
head(10)## # A tibble: 10 x 2
## word n
## <chr> <int>
## 1 review 212
## 2 uk 89
## 3 cup 80
## 4 media 75
## 5 video 73
## 6 letters 72
## 7 day 70
## 8 london 64
## 9 david 63
## 10 world 62I also checked for other short words but there were no other suspiciously short words.
cleaned_theguardian_jan27 <- cleaned_theguardian_jan27 %>%
mutate(word_length=nchar(word, type = "chars", allowNA = FALSE, keepNA = NA))
table(cleaned_theguardian_jan27$word_length)##
## 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
## 159 706 1971 4474 5453 5154 4686 3000 1842 1139 499 242 117 48 13
## 16 20 21
## 4 1 1I want to assign a sentiment to each word to see if the words used in the article titles were positive or negative. (I realise that the “hat a that”" I removed would have disappeared when doing the inner join but I think that there is value in doing some cleaning.)
bing <- get_sentiments("bing")
cleaned_theguardian_jan27_sentiment<- cleaned_theguardian_jan27 %>%
inner_join(bing, by="word") Now each word has been classified as either negative or positive and we can look at the distribution over time.
cleaned_theguardian_jan27_sentiment %>%
select(web_publication_year, sentiment) %>%
group_by(web_publication_year, sentiment) %>%
mutate(sentiment_count=n()) %>%
distinct() %>%
ggplot(data=., aes(x=web_publication_year, y=sentiment_count, fill=sentiment)) + geom_col() + ylab("Count") + xlab("Year of publication") + ggtitle("Sentiment of words in titles")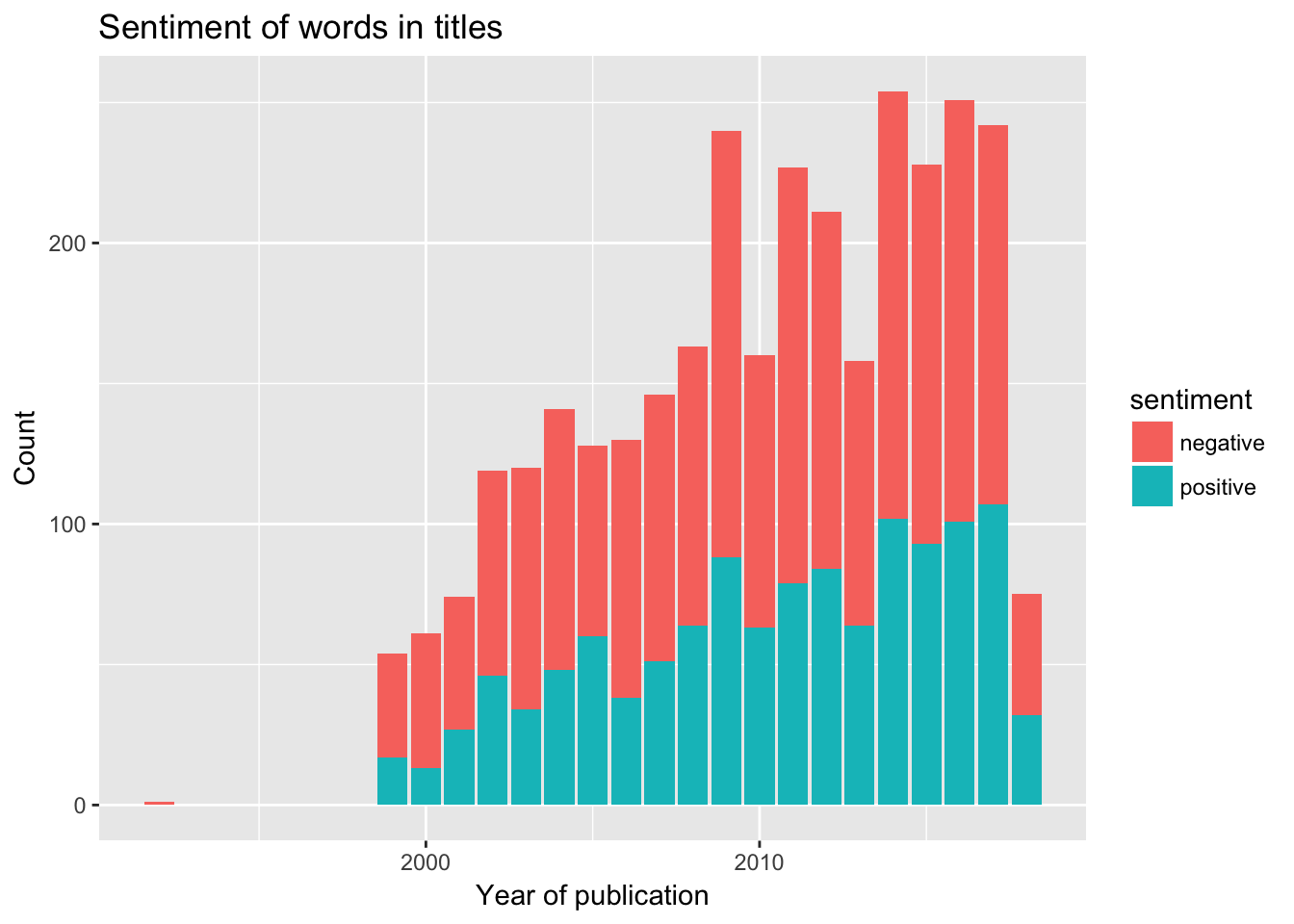
Unfortunately it looks like most of the words used in the titles on my birthday over the years have been negative. Causality? I am not going to let that stop me from having a good time today.